Codes correcteurs#
Quelques Références:
Textes d’agrégation:
Introduction#
Objectif du codage#
Un expéditeur Alice transmet un message \(m\) à Bob sur un canal bruité.
Problématique
Comment Bob peut-il détecter l’existence d’erreurs de transmission
Comment Bob peut-il corriger des erreurs éventuelles
Note
Contrairement à la cryptographie, la problématique n’est pas de se protéger d’un tiers malicieux, mais d’un bruit aléatoire.
Exemples d’applications
NASA/CNES/…: communication avec des sondes et satellites
CD / DVD
Transfert de données par Internet (TCP, CRC, MD5 checksum)
Téléphones portables
Quelles sont les contraintes spécifiques à chacune de ces applications?
Premiers exemples de codes#
Exemple: Langages humains!
Syntaxe: orthographe, grammaire, lexique
Anglais: \(500000\) mots de longueur moyenne \(10\) sur en gros \(26^{10}\), soit une proportion de \(10^{-9}\)
Exemple: pomme, abrucot, poime (pomme, poire, prime, poème)
Sémantique: sens, contexte, …
Exemple: codage de parité sur 7 bits
Alice veut envoyer le message \(m = 0100101\)
Elle le code en un mot à 8 bit avec un nombre pair de 1, en rajoutant un bit de parité: \(c = 01001011\)
Le code est transmis \(c\) et éventuellement altéré
Bob reçoit \(c'\) et regarde s’il y a un nombre pair de 1:
Si non, comme pour \(c' = 01101011\), Bob détecte qu’il y a eu erreur
Si oui comme pour \(c' = 10001011\), Bob suppose que \(c=c'\)
Premiers concepts#
Définitions
Un code \(C\) est un sous-ensemble de mots dans \(M:=A^{n}\), où
\(A\) est un alphabet, comme \(A:=\mathbb{Z}/q\mathbb{Z}= \{0,1,...,q-1\}\) .
Typiquement \(q=2\) (codes binaires).\(n\) est un entier, la dimension du code
Codage: on transforme le message envoyé \(m\) en un mot \(c\) du code.
Transmission: en passant à travers le canal, \(c\) devient \(c'\).
Détection d’erreur: on essaye de déterminer si \(c=c'\); approximation: on teste si \(c'\) est dans \(C\)
Correction d’erreur: on essaye de retrouver \(c\) à partir de \(c'\).
Décodage: on retrouve le message \(m\) à partir de \(c\).
Décodage par distance de Hamming#
Définition
Distance de Hamming entre deux mots: nombre de lettres qui diffèrent (en comparant lettre à lettre).
Stratégie:
Détection d’erreur: est-ce que \(c'\) est dans le code \(C\)?
Correction d’erreur par distance minimale: on renvoie le mot de \(C\) le plus proche de \(c'\).
Exercice: Est-ce raisonnable?
On suppose que lors de la transmission chaque lettre a une probabilité \(p\) d’être corrompue, indépendemment des autres.
Calculer la probabilité qu’un mot de longueur \(n\) arrive intact? Avec une erreur au plus? Avec deux erreurs au plus?
Application numérique:
n = 7; p = 0.1
(1-p)^n
(1-p)^n + n*p*(1-p)^(n-1)
(1-p)^n + n*p*(1-p)^(n-1) + binomial(n,2) * p^2*(1-p)^(n-2)
n = 7; p = 0.01
(1-p)^(n-1)
(1-p)^n + n*p*(1-p)^(n-1)
(1-p)^n + n*p*(1-p)^(n-1) + binomial(n,2) * p^2*(1-p)^(n-2)
Définitions
Capacité de détection: \(D(C)\) nombre maximal d’erreurs que l’on est sûr de détecter
Capacité de correction: \(e(C)\) nombre maximal d’erreurs que l’on est sûr de corriger
Distance \(d(C)\) du code: distance minimale entre deux points distincts du code
Formalisation#
Pour formaliser cela, il est pratique d’introduire la notion de boule naturellement associée à une métrique: étant donné \(x\in M\) et un entier \(k\geq 0\), la boule de centre \(x\) et de rayon \(k\) est:
Alors:
Cas dégénérés#
Lorsque \(|C|\leq 1\), on prendra par convention \(d(C)=+\infty\). Cela peut paraître plus naturel en prenant la définition alternative:
Exercice: en petite dimension
On fixe \(A=\mathbb{Z}/2\mathbb{Z}\) (codes binaires).
Trouver tous les codes de \(M=A^n\) pour \(n=1\), \(n=2\), \(n=0\).
Pour chacun d’entre eux, donner la distance \(d(C)\), la capacité de détection \(D(C)\), la capacité de correction \(e(C)\). Dessiner les boules de centres dans \(C\) et de rayon \(e(C)\).
Permettent-t’ils de corriger une erreur?
Donner un code de \(M=A^3\) permettant de corriger une erreur.
Peut-on faire mieux?
Proposition
Capacité de détection: \(D(C) = d(C) - 1\).
Capacité de correction: \(e(C) = \llcorner\frac{d(C)-1}2\lrcorner\).
Borne de Hamming, codes parfaits#
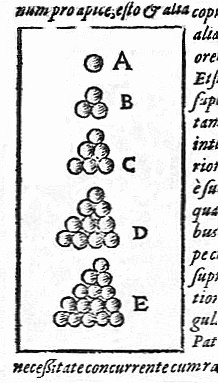
Problème: Kepler discret
On se fixe un alphabet \(A\) avec \(q=|A|\), une dimension \(n\) et une capacité de correction \(e\). Combien de mot peut on coder au maximum?
De manière équivalente: combien de boules non intersectantes de rayon \(e\) peut-on faire rentrer dans \(M\)?
Exemples: visualisation des boules de rayon \(e\) autour de quelques codes binaires
Chargement de quelques fonctions, et configuration des plots 3D:
%run "codes_correcteurs.py"
from sage.plot.plot3d.base import SHOW_DEFAULTS
SHOW_DEFAULTS['frame'] = False
SHOW_DEFAULTS['aspect_ratio'] = [1,1,1]
SHOW_DEFAULTS['viewer'] = 'threejs'
Les boules dans \(M=A^3\) pour \(A=\mathbb{Z}/q\mathbb{Z}\):
@interact
def _(r=slider(0,3,1), q=slider(2,7,1)):
A = IntegerModRing(q)
M = A^3
return dessin_boules([M.zero()], r)
Le code binaire de triple répétition:
A = GF(2)
M = A^3
C = M.subspace([[1,1,1]])
C.list()
dessin_boules(C,1)
et sur \(A=\mathbb{Z}/3\mathbb{Z}\):
A = GF(3)
M = A^3
M.list()[:9]
C = M.subspace([[1,1,1]])
C.list()
dessin_boules(C,1)
Le code de Hamming:
A = GF(2)
M = A^7
C = codes.HammingCode(A, 3)
C.cardinality()
dessin_boules(C, 1, projection=projection_7_3)
Exercice: Borne de Hamming sur \(|C|\).
Soit \(A=\mathbb{Z}/q\mathbb{Z}\).
Taille de la boule \(B(x,e):=\{y,\quad d(x,y)\leq e\}\) de \(A^n\) de centre \(x\) et de rayon \(e\)? Indication: commencer par \(q=2\) et \(x=0\cdots0\).
Taille de \(A^n\)?
Conclusion?
Solution
Application numérique:
@interact
def _(q=slider(1,7,default=2), n=slider(0,10, default=3), e=slider(0,10,default=1)):
m = q^n
b = sum(binomial(n,k)*(q-1)^k for k in range(0, e+1))
print(f"|M|={m}, |B(x,e(C))|={b}, |C|≤ {1.0*m/b:.2}")
Définition: code parfait
Un code \(C\) est parfait si on a égalité: \(|C| |B(x,e(C))| = |A^n|\), i.e.
Exemples
Dans tous les exemples vus jusqu’ici, les seuls codes parfaits sont les codes triviaux, le code de triple répétition sur un alphabet à deux lettres et le code de Hamming.
Problème
Algorithmes de codage? de décodage?
Codes linéaires#
Principe: on rajoute de la structure pour rendre les algorithmes plus efficaces.
Définition
Un code linéaire est un sous-espace vectoriel de \(A^n\), où \(A\) est un corps fini.
Commençons par un petit échauffement.
Exercice: algèbre linéaire sur \(A=\mathbb{Z}/2\mathbb{Z}\), à la main
Soit \(H\) la matrice:
A = GF(2); A
H = matrix(A, [[0,1,1,1, 1,0,0],
[1,0,1,1, 0,1,0],
[1,1,0,1, 0,0,1]]); H
Appliquez le pivot de gauss à \(H\).
Est-ce que les vecteurs \((1,1,0,0,1,1,0)\) et \((1,0,1,1,1,0,1)\) sont dans le sous-espace vectoriel engendré par les lignes de \(H\)?
Conclusion?
Solution:
H
H[1], H[0] = H[0], H[1]
H
H[2] = H[2] + H[0]
H
H[2] = H[2] + H[1]
H
H[0] = H[0] + H[2]
H[1] = H[1] + H[2]
H
u = vector(A, (1,1,0,0,1,1,0))
v = vector(A, (1,0,1,1,1,0,1))
Question
Est-ce que \(u\) est dans le sous-espace vectoriel engendré par les lignes de \(H\)?
On cherche \(a,b,c\) tels que \(u = a H[0] + b H[1] + c H[2]\)
H
u
u = u - H[0]
u
u = u - H[1]
u
Donc \(u\) est dans le sous-espace engendré par les lignes de \(H\)
v
H
v = v - H[0]
v
v = v - H[2]
v
Donc \(v\) n’est pas dans ce sous-espace
Exemples#
Exemple: bit de parité
Sept bits plus un huitième bit dit de parité tel que le nombre total de bit à \(1\) est pair.
v: mon mot
\(v_0 + v_1 + v_2 + v_3 + v_4 + ... + v_7=0\) sssi le nombre de bit à est pair
Exemple: code de Hamming \(H(7,4)\)
Quatre bits \(\left(a_{1},a_{2},a_{3},a_{4}\right)\) plus trois bits de redondance \(\left(a_{5},a_{6},a_{7}\right)\) définis par:
Algorithmes#
Comment coder un message en un mot du code?#
Matrice génératrice (base du code):
G = C.matrix(); G
M = A^4
m = M([1,0,1,0])
c = m * G; c
Comment décoder un mot du code en un message?#
Du fait de la forme de la matrice génératrice:
G
le mot du code c est simplement obtenu en ajoutant des bits
supplémentaires à la fin du mot original. C’est une propriété
souhaitable des codes correcteurs car elle permet de bien séparer
information originale et information redondante. En particulier,
décoder est trivial: il suffit de récupérer les quatre premiers bits.
Exemple: la clé de contrôle de votre numéro de sécurité sociale.
Correction d’erreur par syndrome#
Exercice
Partir du mot zéro, le coder, et faire alternativement une erreur sur chacun des bits. Noter le résultat après multiplication par la matrice de contrôle.
Prendre un mot à 4 bits de votre choix, le coder, faire une erreur sur un des 7 bits, corriger et décoder. Vérifier le résultat.
Que se passe-t’il s’il y a deux erreurs?
Soit \(c\) dans le code: alors \(H c = 0\)
Après transmission, on obtient \(c' = c + ϵ\), où \(ϵ\) est l’erreur.
Alors: \(Hc' = H (c + ϵ) = Hc + Hϵ = Hϵ\)
On interprète \(ϵ\) comme une maladie et \(Hϵ\) comme un syndrome de la maladie: ce que l’on vient de calculer, c’est que deux malades ayant la même maladie auront le même syndrome. La réciproque est vraie tant que \(ϵ\) reste dans la capacité de correction (prouvez le!).
Cela nous donne la stratégie du décodage par syndrome suivante:
Précalculer tous les syndromes \(Hϵ\) pour toutes les «maladies» \(ϵ\) dans la capacité de correction, et en faire une table.
Pour corriger \(c'\), on calcule son syndrôme \(Hc'\). S’il est nul, \(c'\) est déjà dans le code: \(c=c'\). Sinon on retrouve dans la table \(ϵ\) tel que \(Hc'=Hϵ\), et on corrige \(c'\) par \(c=c'-ϵ\).
Codes cycliques#
Principe: encore plus de structure pour être encore plus efficace.
Définition
Un code \(C\) est cyclique s’il est stable par rotation des mots:
Les praticiens ont très tôt noté que les codes cycliques avaient de bonnes propriétés.
Plus tard une explication algébrique a été découverte.
Donnons une structure d’anneau quotient à \(M=A^n\) en l’identifiant avec \(A[X]/(X^n-1)\).
Sous cette identification, les mots ci-dessus correspondent à
Remarque
Dans \(A[X]/(X^n-1)\), décalage = multiplication par \(X\).
Par exemple, pour \(A[X]/(X^7-1)\):
Correspondance
Codes cycliques \(\longleftrightarrow\) idéaux dans \(A[X]/(X^n-1)\).
Algorithmique
Soit \(g\) un diviseur de \(X^n-1\), et \(h\) tel que \(gh=X^n-1\).
Code: idéal engendré par \(g\)
Codage: \(m\mapsto mg\)
Détection d’erreur: \(c*h=0\)
Décodage: division par \(g\) modulo \(X^n-1\) (par ex. par Euclide étendu)
Codes BCH
On peut construire des codes cycliques de capacité de correction déterminée à l’avance. Pour en savoir plus, voir Wikipedia, Codes BCH.
Codage par interpolation (Reed-Solomon)#
Mise en jambe#
Exercice (secret partagé)
Un vieux pirate est sur son lit de mort. Dans sa jeunesse il a enfoui un Fabuleux Trésor dans la lagune de l’Ile de la Tortue, quelque part à l’est du Grand Cocotier. Il a réuni ses dix lieutenants préférés pour leur transmettre l’information secrète indispensable: la distance entre le Grand Cocotier et le Trésor. Connaissant bien ses lieutenants, et dans un étonnant dernier sursaut de justice, il ne voudrait pas qu’une conjuration de quelques uns d’entre eux assassine les autres pour empocher seuls le trésor. En tenant cependant compte de la mortalité habituelle du milieu, il souhaite donner une information secrète à chacun de ses lieutenants pour que huit quelconques d’entre eux puissent retrouver ensemble le trésor, mais pas moins. Comment peut-il s’y prendre?
Solution
Par interpolation!
Application aux CD/DVD: Codage CIRC#
Paramètres du système de codage:
un alphabet donné par un corps fini \(GF(q)\).
trois entiers \(k\), \(d\), et \(l\) avec \(d\leq l\)
\(l\) points d’évaluation \(x_1,\ldots,x_l\) dans \(GF(q)\)
un procédé D de codage sur \(GF(q)^k\) avec bonne capacité de détection
Décodage
On utilise D pour détecter les blocs corrompus. On les jette.
S’il en reste au moins \(d\): on retrouve chaque \(P_i\) à partir de ses valeurs sur \(d\) points d’évaluation.
Comment tester si un mot appartient au code?#
Avec Sage:
Matrice de contrôle (équations définissant le code):
Test d’appartenance au code:
Refaites le à la main!
Le code lui-même est le noyau de \(H\):
Refaites le à la main!
Est-ce que l’on pourrait trouver \(C\) encore plus rapidement?
Oui:
Exercice
Combien y-a-t’il de mots dans le code de Hamming \(C=H(7,4)\)?
Calculer la distance de ce code (indice: se ramener en zéro!)
Quelle est sa capacité de détection? de correction? Est-il parfait?
Solution: